C/C++
C/C++
一. C++编程习惯与编程要点
参考:https://mp.weixin.qq.com/s/eFFc74OpA1ca2LlCB94Siw
1. 代码注释
/**
* 每一行都用一个*开始
* 写好注释
*/
/* */ 不能嵌套使用
2. 腾讯代码安全指南
二. 零散笔记
1. 字符转数字
#include <stdio.h>
atof() // 转成浮点型
atoi() // 转成int型
2. 纯字符串,去掉转义
std::string str = R"(aaaa\t\nbbbb)";
std::cout << str << std::endl; // aaaa\t\nbbbb
3. 常量指针和指针常量
常量指针
提示
指针指向的内容是常量。不能修改 p 指向的内容
*pconst int *p = &a;
指针常量
提示
指针是个常量。不能修改 p 的指向
int * const p = &a;
4. 自增和自减
i++
先运算,再自增
x = i++; //先让x变成i的值1,再让i加1
++i
先自增,再运算
x = ++i; //先让i加1, 再让x变成i的值1
5. 睡眠
Windows下
#include <windos.h>
Sleep(500); // 单位:毫秒
Linux下
#include <unistd.h>
sleep(5); // 单位:秒
usleep(5) // 单位:微秒
通用:
#include <thread>
this_thread::sleep_for(chrono::seconds(1))
6. 静态链表
定义用数组来描述链表叫做静态链表
| 游标 | 5 | 2 | 3 | 4 | 5 | 6 | 7 | ... | 1 |
|---|---|---|---|---|---|---|---|---|---|
| 数据 | A | C | D | E | ... | ||||
| 下标 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | ... | 999 |
#define MAXSIZE 100
typedef struct {
string data; //数据
int cur; //游标Cursor
}StaticLinkList[MAXSIZE];
则对链表进行初始化相当于初始化数组:
StaticLinkList s = {
{"a",1},
{"b",2},
{"c",0} //最后一个元素的cursor指向0
};
int i = 0;
do {
cout << s[i].data << endl;
i = s[i].cur;
} while (i);
获取链表长度
int length(StaticLinkList s) {
int count = 0,i = 0;
do {
i = s[i].cur;
count++;
} while (i);
return count;
}
静态链表的插入操作
比如要把B插入A的后面,则

静态链表的删除操作
把要插入位置的前一个cursor指向下标为插入位置的cursor即可
实操案例
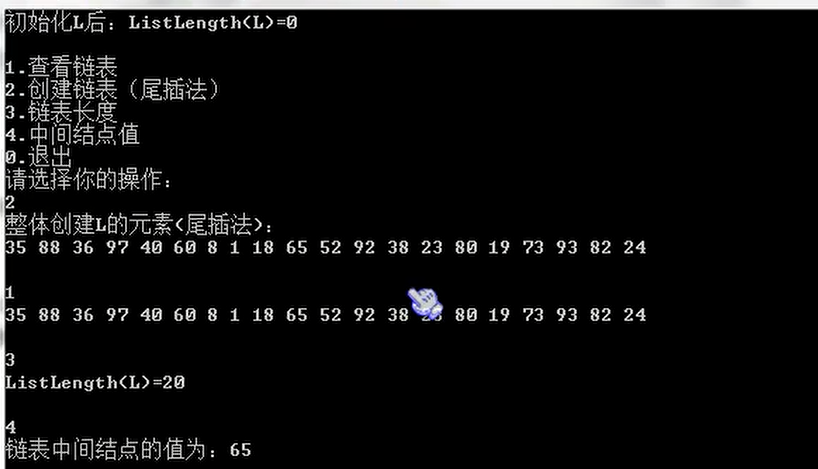
写一个完整的程序,实现随机生成20个元素的链表(尾插法、头插法任意),用快速查找法快速查找中间节点的值并显示
快速查找法:利用快慢指针原理:
设置连个节点*serch、*mid,都指向单链表的头节点,其中*serch的移动速度是*min的2倍。当*search指向末尾节点的时候,min就正好在中间了,这也是标尺的思想。
7. C++ 通过 Python API 来调用 Python
https://hkrb7870j3.feishu.cn/docx/VJ0hdyhWUofyw0xutfYcS1OGnvf
三. STL
1. 容器
array
相关信息
array 是固定大小的顺序容器,它们保存了个以严格的线性顺序排列的特定数量的元素。
| 方法 | 说明 |
|---|---|
| begin | 返回指向数组容器中第一个元素的迭代器 |
| end | 返回指向数组容器中最后一个元素之后的理论元素的迭代器 |
bitset
deque
forward_list
list
map
初始化
map<string, int> m1;插入
m1.insert(pair<string, int>("xxl", 150)); m1.insert(pair<string, int>("xxx", 125));m1.emplace("a", 10); m1.emplace("b", 20);遍历
for (map<string, int>::iterator it = m1.begin(); it != m1.end(); it++) { cout << it->first << ", " << it->second << endl; }
queue
初始化
queue<int> q;入队
q.push_back(100);出队
q.pop()获取队头元素
q.front();
set
- 初始化
- 插入
- 遍历
stack
初始化
stack<int> stk;stack<int> stk {1, 2, 3}入栈
stk.push(100);弹栈
stk.pop();获取栈顶元素
stk.top();判断栈是否为空
stk.isEmpty();
unordered_map
unordered_set
vector
初始化
vector<int> v;vector<int> v(10) // 创建一个大小为10的数组vector<int> v(10, 0) // 创建一个大小为10, 且全部元素初始化为 0vector<int> v{ 1,2,3,4,5,6 }; // 设定元素插入
v.push_back(10); v.push_back(30);遍历
// 使用 at() 函数来遍历, 可以判断是否越界 for (int i = 0; i < v.size(); i++) { cout << v.at(i) << endl; }// 使用 [] 来遍历 for (int i = 0; i < v.size(); i++) { cout << v[i] << endl; }// 使用迭代器来遍历 for (vector<int>::iterator it = v.begin(); it != v.end(); it++) { cout << *it << endl; } // 使用自动判断类型 for (auto it = v.begin(); it != v.end(); it++) { cout << *it << endl; }
2. 算法
3. 迭代器
4. 仿函数
5. 适配器(配接器)
6. 空间配置器
四. 线程、进程
#include <thread>
void func1(int i){
std::cout << "T1" << i << std::endl;
}
void func2(){
std::cout << "T2" << std::endl;
}
int main(){
thread t1(func1, 100);
thread t1(func2);
t1.join();
t2.join();
}
1. 线程
概念
相关信息
进程线程区别
线程之间共享和非共享资源
NPTL
线程操作函数
int pthread_create(pthread_t *thread, const pthread_attr_t *attr, void *(*start_routine)(void *), void *arg);
pthread_t pthread_self(void);
int pthread_self(pthread_t t1, pthread_t2);
void pthread_exit(void *retval);
int pthread_join(pthread_t thread, void **retval);
int pthread_detach(pthread_t thread);
int pthread_cancel(pthread_t thread);
#include <stdio.h>
#include <pthread.h>
#include <string.h>
#include <unistd.h>
void *callback(void *arg) {
printf("child thread...\n");
printf("arg value: %d\n", *(int *)arg);
return NULL;
}
int main(){
pthread_t tid;
int num = 10;
// 创建一个子线程
int ret = pthread_create(&tid, NULL, callback, (void *)&num);
if (0 != ret) {
char *errstr = strerror(ret);
printf("error: %s\n", errstr);
}
for (int i = 0; i < 5; i++) {
printf("%d\n", i);
}
sleep(2);
return 0;
}
线程同步
相关信息
线程的主要优势在于,能够通过全局变量来共享信息。不过,这种便捷的共享是有代价的:必须确保多个线程不会同时修改同一个变量,或者某一线程不会读取正在由其它线程修改的变量。
临界区是指访问某一共享资源的代码片段,并且这段代码的执行应为原子操作,也就是同时访问同一共享资源的其它线程不应终端该片段的执行。
线程同步指当有一个线程在对内存进行操作时,其他线程都不可以对这个内存地址进行操作,直到该线程完成操作,其它线程才能对该内存地址进行操作,而其它线程则处于等待状态。
互斥量
互斥量相关操作函数:
int pthread_mutex_init(pthread_mutex_t *restrict mutex, const pthread_mutexattr_t *restrict attr);
int pthread_mutex_destroy(pthread_mutex_t *mutex);
int pthread_mutex_lock(pthread_mutex_t *mutex);
int pthread_mutex_trylock(pthread_mutex_t *mutex);
int pthread_mutex_unlock(pthread_mutex_t *mutex);
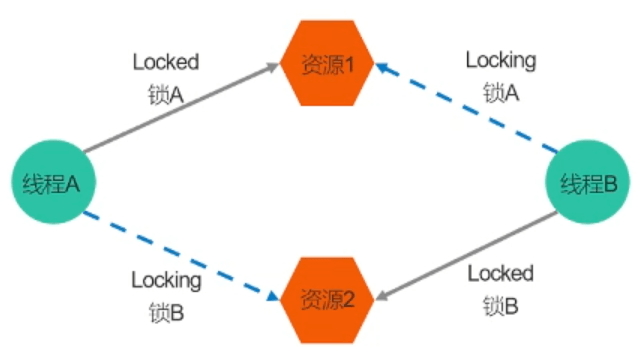
死锁
相关信息
有时,一个线程需要同时访问两个或更多不同的共享资源,而每个资源又都由不同的互斥量管理。当超过一个线程加锁同一组互斥量时,就有可能发生死锁。
两个或两个以上的进程在执行过程中,因争夺共享资源而造成的一种互相等待的现象,若无外力作用,它们都将无法推进下去。此时称系统处于死锁状态或系统产生了死锁。
死锁的几种场景:
忘记释放锁
重复加锁
- 多线程多锁,抢占锁资源
读写锁
生产者消费者模型
条件变量
条件变量的类型:pthread_cond_t
int pthread_cond_init(pthread_cond_t *restrict cond, const pthread_condattr_t *restrict attr);
int pthread_cond_destroy(pthread_cond_t *cond);
int pthread_cond_wait(pthread_cond_t *restrict cond, pthread_mutex_t *restrict mutex);
int pthread_cond_timewait(pthread_cond_t *restrict cond, pthread_mutex_t *restrict mutex, const struct timespec *restrict abstime);
int pthread_cond_signal(pthread_cond_t *cond);
int pthread_cond_broadcast(pthread_cond_t *cond);
信号量
信号量的类型:sem_t
int sem_init(sem_t *sem, int pshared, unsigned int value);
int sem_destroy(sem_t *sem);
int sem_wait(sem_t *sem);
int sem_trywait(sem_t *sem)
int sem_timedwait(sem_t *sem, const struct timespec *abs_timeout);
int sem_getvalue(sem_t *sem, int *sval);
多线程
线程池
2. 进程
基本概念
进程的状态
进程相关指令
查看进程
ps aux
ps ajx
- a: 显示终端上的所有进程,包括其它用户的进程
- u: 显示进程的详细信息
- x: 显示没有控制终端的进程
- j: 列出与作业控制相关的信息

STAT参数意义:
| 参数 | 意义 |
|---|---|
| D | 不可中断 Uninterruptible (usually IO) |
| R | 正在运行,或在队列中的进程 |
| S | 处于休眠状态 |
| T | 停止或被追踪 |
| Z | 僵尸进程(Zoombi) |
| W | 进入内存交换 (从内核2.6开始无效) |
| X | 死掉的进程 |
| < | 高优先级 |
| N | 优先进程 |
| s | 包含子进程 |
| + | 位于前台的进程组 |
杀死进程
注
并不是真的去杀死进程,而是给进程发送某个信号
kill [signal] pid
kill -l # 列出所有信号
kill -SIGKILL 进程ID
kill -9 进程ID
killall name # 根据进程名杀死进程
进程号相关函数
pid_t getpid(void); // 获得当前进程ID
pid_t getppid(void) // 获得父进程ID
pid_t getpgid(pid_t, pid) // 获得组进程ID
进程创建
相关信息
系统允许一个进程创建新进程,新进程即为子进程,子进程还可以创建新的子进程,形成进程树结构模型
#include <sys/types.h>
#include <unistd.h>
pid_t fork(void);
返回值:
- 成功:子进程中返回0,父进程中返回子进程 ID
- 失败:返回-1
失败的2个原因:
- 当前系统的进程数已经达到了系统规定的上限,这时 errno 的值被设置为 EAGAIN
- 当系统内存不足,这时 errno 的值被设置为 ENOMEN
exec 函数族介绍
进程控制
进程退出
孤儿进程
相关信息
父进程运行结束,但子进程还在运行 (未运行结束),这样的子进程就称为孤儿进程 (Orphan Process) 。
每当出现一个孤儿进程的时候,内核就把孤儿进程的父进程设置为 init,init 进程会循环地 wait() 它的已经退出的子进程。这样,当一个孤儿进程凄凉地结束了其生命周期的时候,init 进程就会代表党和政府出面处理它的一切善后工作。因此孤儿进程并不会有什么危害。
僵尸进程
相关信息
每个进程结束之后,都会释放自己地址空间中的用户区数据,内核区的 PCB 没有办法白己释放掉,需要父进程去释放。
进程终止时,父进程尚末回收,子进程残留资源(PCB)存放于内核中,变成僵尸 (Zombie)进程。
僵尸进程不能被 kill -9 杀死,这样就会导致一个问题,如果父进程不调用 wait() 或 waitpid() 的话,那么保留的那段信息就不会释放,其进程号就会一直被占用,但是系统所能使用的进程号是有限的,如果大量的产生僵尸进程, 将因为没有可用的进程号而导致系统不能产生新的进程,此即为僵尸进程的危害,应当避免
进程回收
相关信息
在每个进程退出的时候,内核样放该进程所有的资源、包括打开的文件、占用的内存等。但是仍然为其保留一定的信息,这些信息主要指进程控制块 PCB 的信息(包括进程号、退出状态、运行时间等)。
父进程可以通过调用 wait 或 waitpid 得到它的退出状态同时彻底清除掉这个进程。
wait() 和 waitpid() 函数的功能一样,区别在于,wait() 函数会阻塞,waitpid() 可以设置不阻塞,waitpid() 还可以指定等待哪个子进程结束。
注意:一次 wait 或 waitpid 调用只能清理一个子进程,清理多个子进程应使用循环。
退出信息相关宏函数
进程间通信
进程间通讯概念
Linux 进程间通信的方式
匿名管道(管道)
有名管道(命名管道)
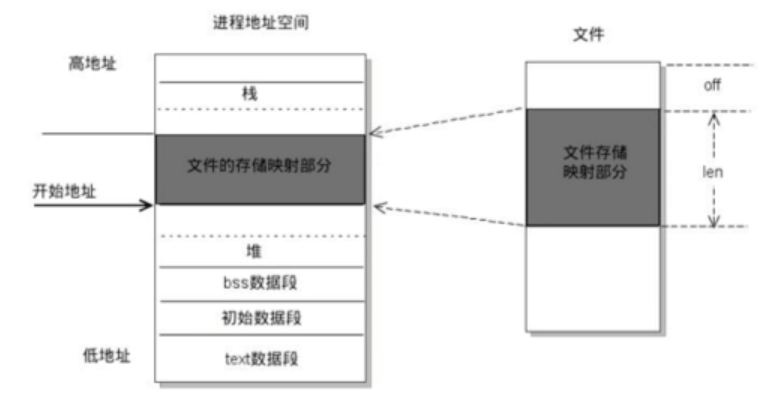
内存映射
相关信息
内存映射 (Memory-mapped I/O) 是将磁盘文件的数据映射到内存,用户通过修改内存就能修改磁盛文件。
#include <sys/mmam.h>
void *mmp(void *addr, size_t length, int port, int flags, int fd, off_t offset);
int mumap(void *addr, size_t length);
信号
概述
共享内存
使用步骤
相关函数
共享内存操作命令
多进程
进程池
五. 静态库动态库
1. 什么是库
相关信息
库文件是计算机上的一类文件,可以简单的把库文件看成是一种代码仓库,它提供给使用者一些可以直接拿来用的变量、函数或类。
库是特殊的一种程序,编写库的程序和编写一般的程序区别不大,只是库不能单独运行。
库文件有两种,静态库和动态库(共享库),区别是:
- 静态库在程序的链接阶段被复制到了程序中
- 动态库在链接阶段没有被复制到程序中,而是程序在运行时由系统动态加载到内存中供程序调用
库的好处:1.代码保密 2.方便部署和分发
2. 静态库
命名规则
Linux
libxxx.alib: 前缀(固定)
xxx: 库的名字(自定)
.a: 后缀(固定)
Windows
libxxx.lib
静态库的制作
gcc 获得
.o文件使用
ar工具(archive)将.o文件打包ar rcs libxxx.a xxx.o xxx.or: 将文件插入备存文件中
c: 建立备存文件
s: 索引
3. 动态库
命名规则
Linux
libxxx.solib: 前缀(固定)
xxx: 库的名字(自定)
.so: 后缀(固定)
Windows
libxxx.dll
动态库的制作
gcc 获得
.o文件,得到和位置无关的代码gcc -c -fpic a.c b.c 或 gcc -c -fPIC a.c b.cgcc 得到动态库
gcc -shared a.o b.o -o libcalc.sor: 将文件插入备存文件中
c: 建立备存文件
s: 索引
六. C/C++ 的编译链接
1. 使用 MSVC 编译代码
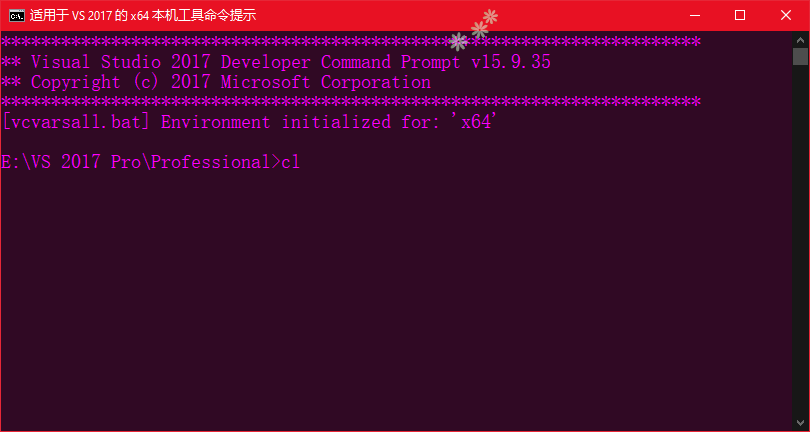
- 打开适用于 vs2017 的 x64 本机工具命令提示
- 输入
cl + "文件绝对路径"或者 输入 g++ 文件名 -o 输出文件名 - 编译完成后,会生成可执行文件.exe,.obj是二进制代码
- 输入文件名即可运行
2. 程序编译步骤
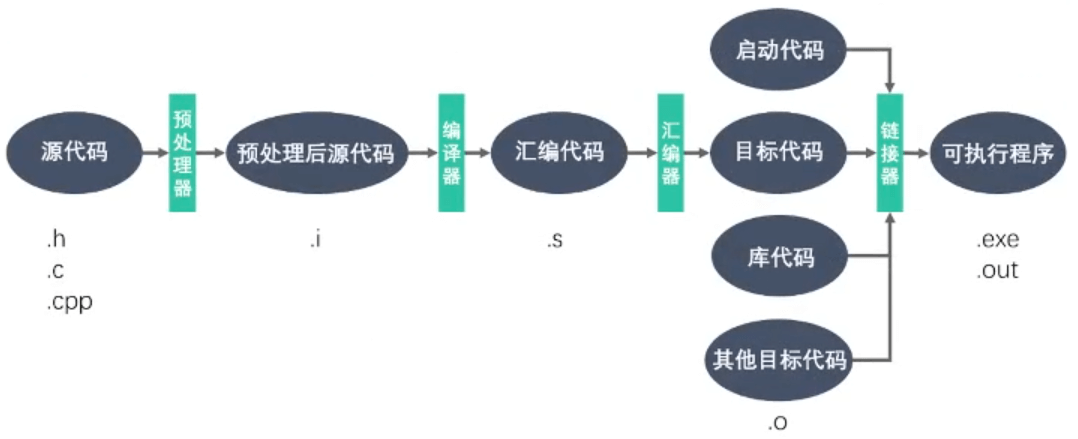
预处理(Preprocessing)``gcc -E *.c > test.ii` ,会把预处理的内容保存到txt
- 预处理指令执行(头文件引入)
- 宏展开
预编译 ``g++ -S test.ii`, 会生成一个test.s文件,就是汇编代码
- 编译(Compilation)
- 汇编(Assembly)``g++ -c test.s`,linux生成.o,windows生成.obj,把汇编转成二进制
编译
gcc -c *.c //生成目标文件链接(Linking)(多个文件链接成一个可执行文件)
gcc main.o add.o sub.o -o demo.exegcc *.o -o demo.exe
3. GCC、G++
GCC 常用参数选项
| GCC 编译选项 | 说明 |
|---|---|
| -E | 预处理指定的源文件,不进行编译(宏替换、去掉注释)。生成 .i 文件 |
| -S | 编译指定的源文件,但是不进行汇编。生成 .s 文件 |
| -c | 编译、汇编指定的源文件,但是不进行链接。生成 .o 文件 |
| -o | |
| -I | |
| -g | |
| -D | |
| -w | |
| -Wall | |
| -On | |
| -l | |
| -L | |
| -fPIC/fpic | |
| -shared | |
| -std |


G++

多文件编译
gcc -c main.c // 会生成一个.o文件
gcc -c add.c // 会生成一个.o文件
gcc -c sub.c // 会生成一个.o文件

链接:
gcc *.o -o demo
或者
gcc main.o add.o sub.o -o demo

但是这样一个文件对应一行的编译,效率很慢,而且当文件有几十个或者几百个时会很复杂、繁琐
4. Makefile
- linux下C/C++编程makefile应用广泛
- 编译移植开源项目,大部分开源项目都基于 makefile,学会 makefile 才能够调试编译过程中的问题
- 手写 makefile 太过于繁琐,自动生成的 makefile 不易于配置,学习本门课程编写自动化 makefile,以后新项目只需要include makefile头文件
Makefile 文件命名和规则
makefile 或 Makefile
Makefile 文件内容
- makefile文件主要包含了5部分内容:
- 显式规则。说明了如何生成一个或多个目标文件。由makefile文件的创作者指出,包括要生成的文件、文件的依赖文件、生成的命令。
- 隐式规则。由于make有自动推导的功能,所以隐式的规则可以比较粗糙地简略书写makefile文件,这是由make所支持的。
- 变量定义。在makefile.文件中要定义一系列的变量,变量一般都是字符串,这与C语言中的宏有些类似。当makefile文件执行时,其中的变量都会扩展到相应的引用位置上。
- 文件指示。其包括3个部分,一个是在一个makefile文件中引用另一个makefile文件;另一个是指根据某些情况指定makefile文件中的有效部分;还有就是定义一个多行的命令。
- 注释。makefile.文件中只有行注释,其注释用“#"字符。如果要在makefile文件中使用“#"字符,可以用反斜框进行转义,如:“#”。
基本语法:
目的:依赖
通过依赖生成目的的命令
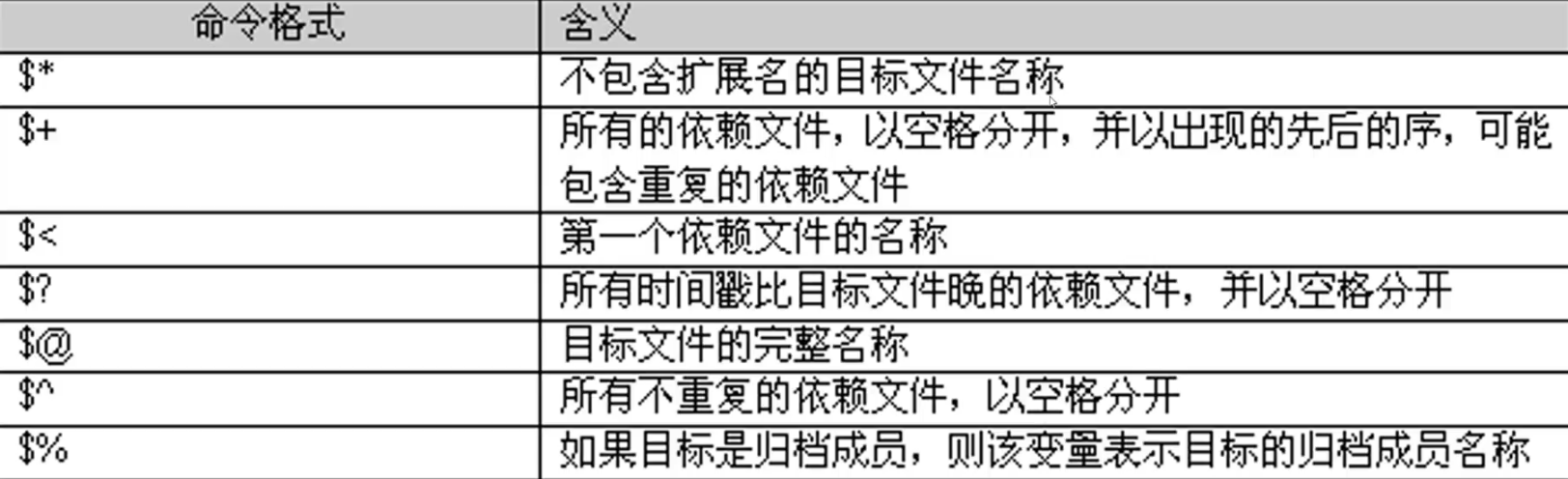
$@ :代表的是目的
创建
touch makefile
编写
math.exe: main.o add.o sub.o
gcc main.o add.o sub.o -o demo.exe
main.o:main.c
gcc -c main.c -o main.o
add.o:add.c
gcc -c add.c -o add.o
sub.o:sub.c
gcc -c sub.c -o sub.o
clean:
rm -f *.o
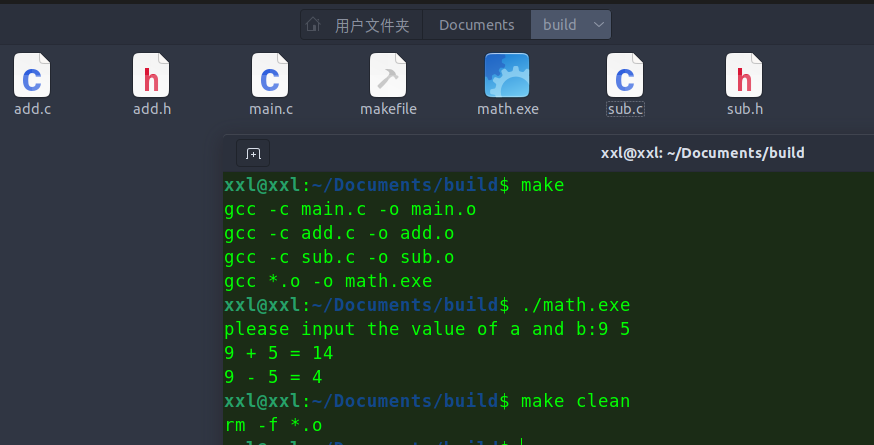
开始编译
make
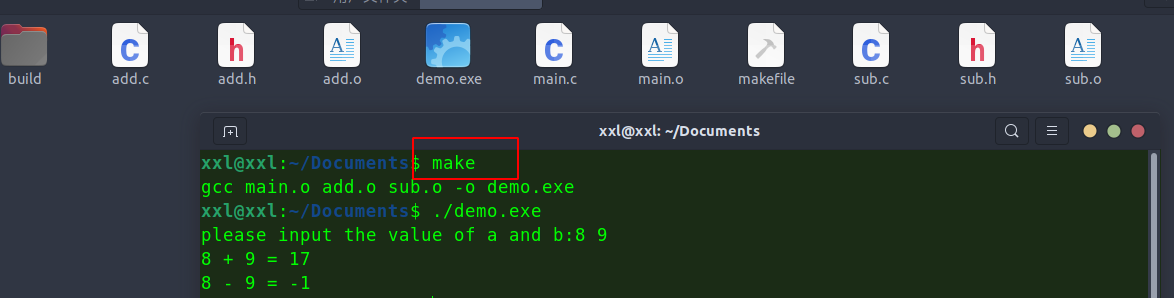
删除.o文件make clean
还有个优化:
< 会依次对应第一行写的.o文件,按照顺序进行编译
math.exe: main.o add.o sub.o
gcc *.o -o $@
%.o:%.c
gcc -c $< -o $@
clean:
rm -f *.o
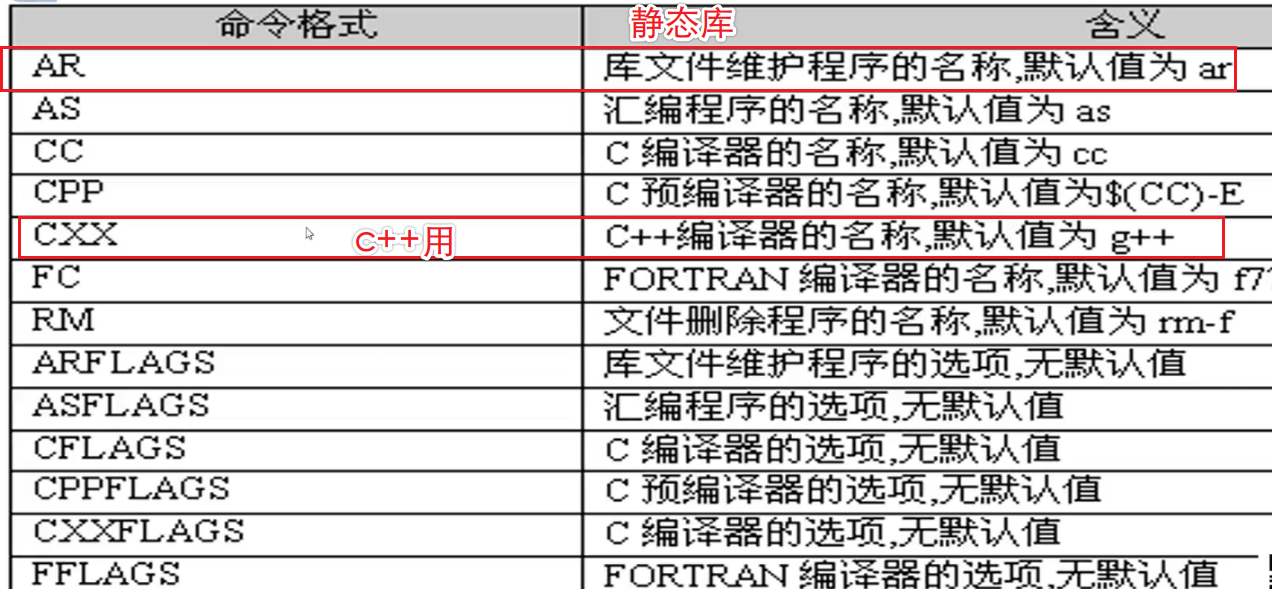
5. makefile语法
变量-常见 预定义变量
# first_make
# $^ 表示依赖 不重复
# $@ 表示目标
# @ 加在命令的前面表示不在终端打印出具体的语句 -加个横杠表示该行命令执行错误后继续往下执行
# 定义一个变量
TARGET=first_make
first_make:first_name.cpp
$(CXX) $^ -o $@ -lpthread
TARGET=first_make # 目标文件
$(TARGET):first_make.cpp xdata.cpp
@#-@rm test
@echo "begin to build $(TARGET)"
@$(CXX):WQ
$^ -o $@ $(LIBS)
@echo "$(TARGET) build success!"
TARGET=first_make # 目标文件
LIBS=-lpthread # 包含的一些库
OBJS=first_make.o xdata.o # 生成的二进制文件
CXXFLAGS=-I./include # 在C++包含的头文件所在位置
$(TARGET):$(OBJS) # 这就是定义变量的好处
@#-@ rm test
@echo "begin to build $(TARGET)"
@$(CXX) $^ -o $@ $(LIBS)
@echo "$(TARGET) build success!"
# 编译完成后,清理中间生成的文件
clean:
$(RM) $(OBJS) $(TARGET)
.PHONY: clean *.clean
要执行目标项,输入命令时要指定 make clean
一般用来清理掉,重新编译
6. GCC编译动态链接库
所谓动态链接库,就是指在代码运行的过程中去加载的
动态库只会把动态库函数的地址复制过来,文件后缀是.so
而静态库会把所有的二进制代码都复制过去,因此静态库的文件会更大一些,文件后缀是.a


静态库

七. GDB
相关信息
GDB 是由
注:表格里面的
/表示或者
| 功能 | 命令 |
|---|---|
| 启动和退出 | gdb 可执行程序 quit/q |
| 给程序设置参数/获取设置参数 | set args 10 20 show args |
| GDB 使用帮助 | help |
| 查看当前文件代码 | List/l 从默认位置显示 list/l 行号 从指定的行显示 list/l 函数名 从指定的函数显示 |
| 设置显示的行数 | show list/listsize set list/listsize 行数 |
| 设置断点 | b/break 行号 b/break 函数名 b/break 文件名:行号 b/break 文件名:函数 |
| 查看断点 | i/info b/break |
| 删除断点 | d/del/delete 断点编号 |
| 设置断点无效 | dis/disable 断点编号 |
| 设置断点生效 | ena/enable 断点编号 |
| 设置条件断点(一般用在循环位置) | b/break 10 if i==5 |
| 运行 GDB 程序 | start 程序停在第一行 run 遇到断点就停 |
| 继续运行,到下一个断点停 | c/continue |
| 向下执行一行代码(不进入函数体) | n/next |
| 向下单步调试(进入函数体) | s/setp finish(跳出函数体) |
| 变量操作 | p/print 变量名(打印变量值) ptype 变量名 (打印变量类型) |
| 自动变量操作 | display 变量名(自动打印指定变量的值) i/info display undisplay |
| 其它操作 | set var 变量名=变量值(循环中用的较多) until (跳出循环) |
八. 文件IO
1. 标准C库IO函数
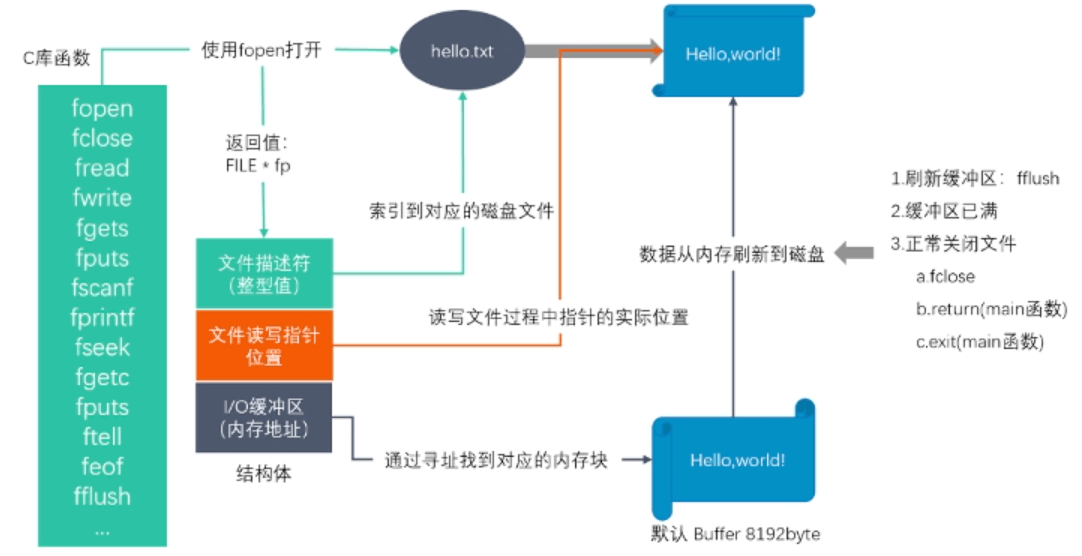
2. 标准C库IO和Linux系统IO的关系
3. 虚拟地址空间
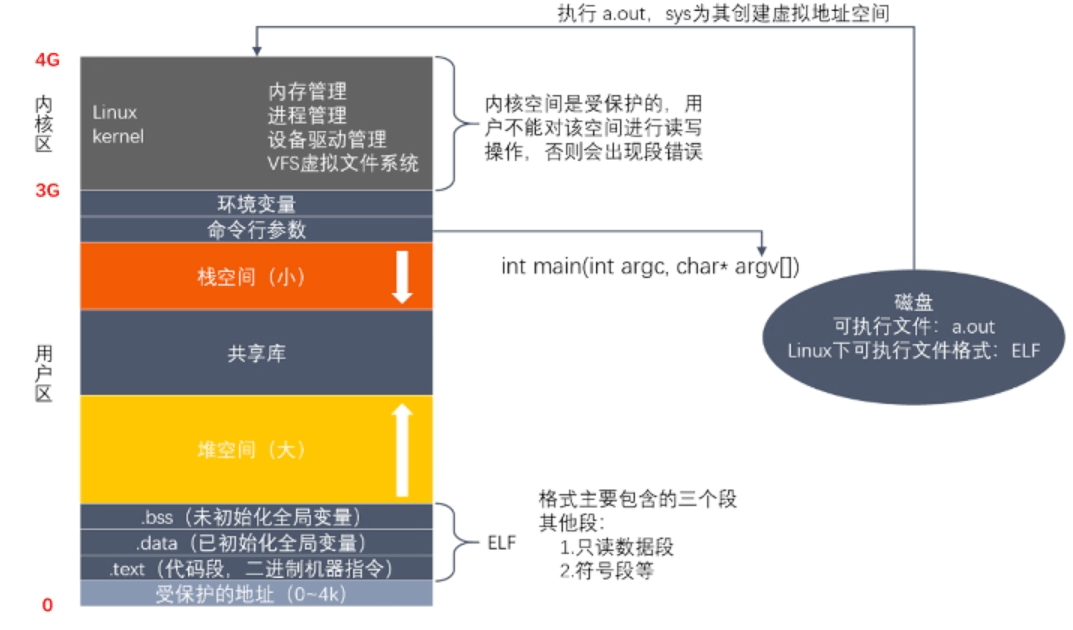
4. 文件描术符
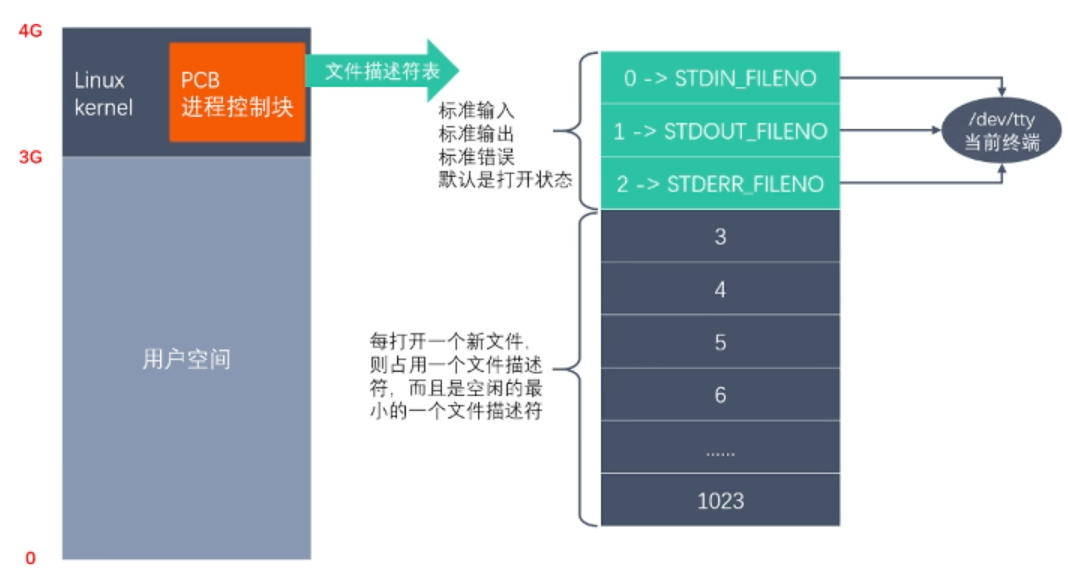
5. Linux系统IO函数
小技巧
使用 man 命令可查看手册,手册一共有8个章节。比如:
查看
lsman ls查看第2章的 open 函数
man 2 open
int open(const char *pathname, int flags);
int open(const char *pathname, int flags, mode_t mode);
ssize_t read(int fd, void *buf, size_t count);
ssize_t write(int fd, const void *buf, size_t count);
off_t lseek(int fd, off_t offset, int whence);
int stat(const char *pathname, struct stat *statbuf);
int lstat(const char *pathname, struct stat *statbuf);
stat 结构体:
struct stat{
dev_t st_dev; //
ino_t st_ino; //
mode_t st_mode; //
nlink_t st_nlink; // 连接
uid_t st_uid;
gid_t st_gid;
dev_t st_rdev;
off_t st_size;
blksize_t st_blksize;
}
6. 文件属性操作函数
7. 目录操作函数
int rename(const char *oldpath, const char *newpath);
int chdir(const char *path);
int mkdir(const char *pathname, mode_t mode);
int rmdir(const char *pathname);
8. 目录遍历函数
DIR *opendir(const char *name);
struct dirent *readdir(DIR, *dirp);
int closedir(DIR, *dirp);
9. dirent 结构体和 d_type
10. dup、dup2 函数
11. fcntl 函数
// 复制文件描述符、设置/获取文件的状态标志
int fcntl(int fd, int cmd, ... /* arg */);
九. 网络编程
1. MAC 地址
相关信息
网卡是一块被设计用来允许计算机在计算机网络上进行通讯的计算机硬件,又称为网络适配器或网络接口卡 NIC。其拥有 MAC 地址,属于 OSI 模型的第 2 层,它使得用户可以通过电缆或无线相互连接。每一个网卡都有一个被称为 MAC 地址的独一无二的 48 位串行号。网卡的主要功能:
数据的封装与解封装
链路管理
数据编码与译码

2. IP地址
相关信息
3. 端口
4. 网络模型
5. 协议
6. 网络通信过程
7. socket介绍
相关信息
所谓 socket(套接字),就是对网络中不同主机上的应用进程之间进行双向通信的端点的抽象。一个套接字就是网络上进程通信的一端,提供了应用层进程利用网络协议交换数据的机制。从所处的地位来讲,套接字上联应用进程,下联网络协议栈,是应用程序通过网络协议进行通信的接口,是应用程序与网络协议根进行交互的接口。
socket 可以看成是两个网络应用程序进行通信时,各自通信连接中的端点,这是一个逻得上的概念。它是网络环境中进程间通信的 API,也是可以被命名和寻址的通信端点,使用中的每一个套接宇都有其类型和一个与之相连进程。通信时其中一个网络应用程序将要传输的一段信息写入它所在主机的 socket 中,该 socket 通过与网络接口卡 (NIC) 相连的传输介质将这段信息送到另外一台主机的 socket 中,使对方能够接收到这段信息。socket 是由 1P 地址和端口结合的,提供向应用层进程传送数据包的机制。
socket 本身有“插座"的意思,在Linux环境下,用于表示进程间网络通信的特殊文件类型。本质为内核借助缓冲区形成的伪文件。既然是文件,那么理所当然的,我们可以使用文件描述符引用套接宇。与管道类似的,Linux 系统将其封装成文件的目的是为了统一接口,使得读写套接字和读写文件的操作一致。区别是管道主要应用于本地进程问通信,而套接字多应用于网络进程间数据的传递。
套接字通信分两部分
- 服务端:被动接受连接,一般不会主动发起连接
- 客户端:主动向服务器发起连接
socket 是一种通信的接口, Linux 和 Windows 都有, 但是有一些细微的差别
8. 字节序
相关信息
现代 CPU 的累加器一次都能装载(至少)4字节(这里考虑 32 位机),即一个整数。那么这4 字节在内存中排列的顺序将影响它被累加器装载成的整数的值,这就是字节序问题。在各种计算机体系结构中,对于字节、宇等的存储机制有所不同,因而引发了计算机通信领域中一个很重要的问题,即通信双方交流的信息单元(比特、字节、字、双宇等等)应该以什么样的顺序进行传送。如果不达成一致的规则,通信双方将无法进行正确的编码/译码从而导致通信失败。
字节序,顾名思义字节的顺序,就是大于一个字节类型的数据在内存中的存放顺序(一个字节的数据当然就无需谈顺序的问题了)。
字节序分为大端字节序(Big- Endian)和小端字节序 (Little-Endian)。
大端字节序是指一个整数的最高位字节(23 ~ 31 bit)存储在内存的低地址处,低位字节(0 ~ 7bit)存储在内存的高地址处;
小端字节序则是指整数的高位字节存储在内存的高地址处,而低位字节则存储在内存的低地址处。
字节序举例
小端字节序
0x 11 22 33 44 12 34 56 78
大端字节序
0x 12 34 56 78 11 22 33 44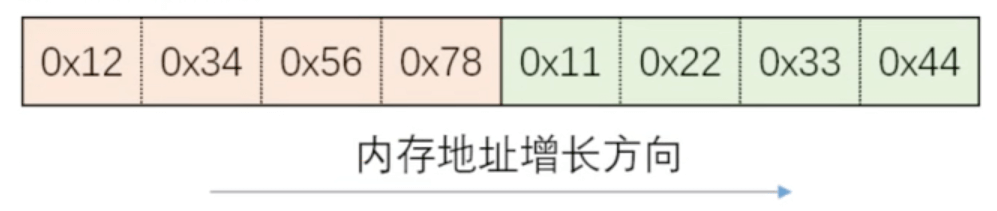
字节序转换函数
相关信息
9. socket地址
10. IP地址转换
字符串IP-整数,主机、网络字节序的转换
11. TCP
TCP通信流程
套接字函数
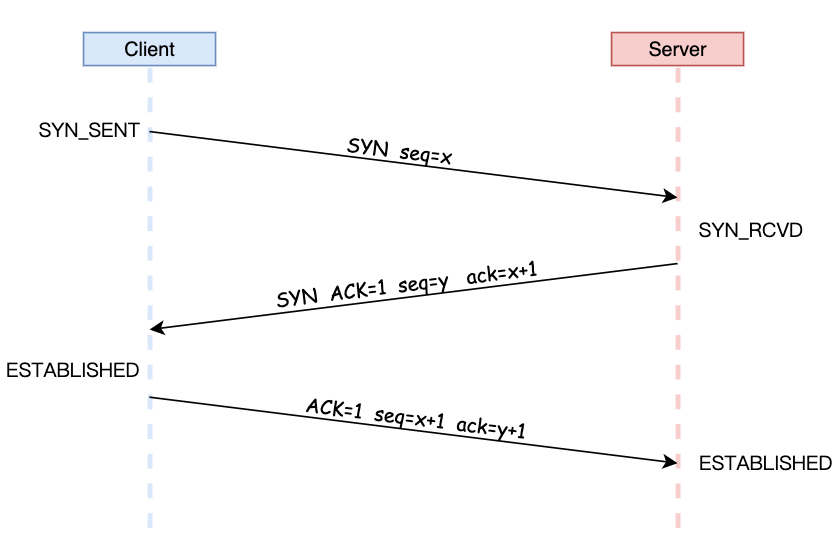
TCP三次握手
TCP滑动窗口
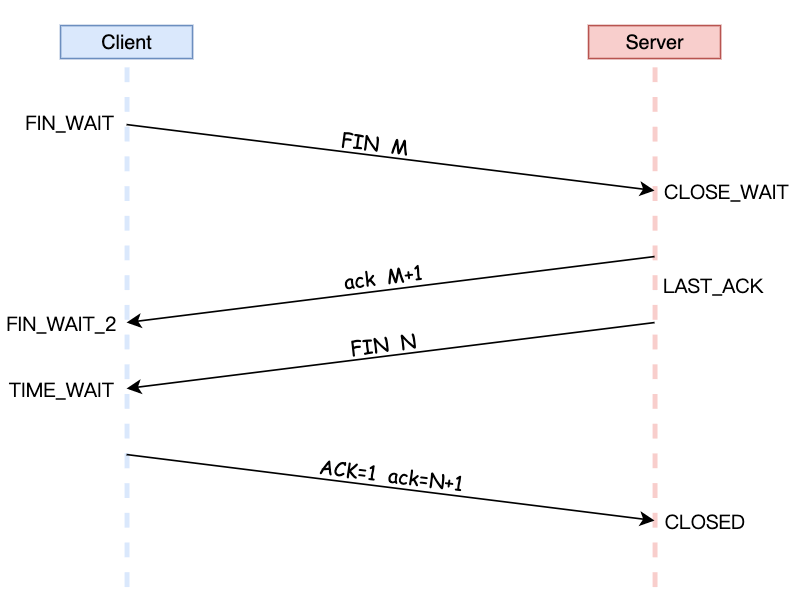
TCP四次挥手
TCP状态转换
12 端口复用
13. I/O 多路复用(I/O多路连接)
相关信息
I/O 多路复用使得程序能同时监听多个文件描述符,能够提高程序的性能,Linux 下实现 I/0 多路复用的系统调用主要有 select、poll 和 epoll。
select
主旨思想
首先要构造一个关于文件描述符的列表,将要监听的文件描述符添加到该列表中。
调用一个系统函数,监听该列表中的文件描述符,直到这些描述符中的一个或者多个进行 I/O 操作时,该函数才返回。
这𠆤函数是阻塞
函数对文件描述符的检测的操作是由内核完成的
在返回时,它会告诉进程有多少(哪些) 描述符要进行 I/O 操作。
// sizeof(fd_set) = 128 1024
#include <sys/time.h>
#include <sys/types.h>
#include <unistd.h>
#include <sys/select.h>
int select(int nfds, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);
- nfds: 委托内核检测的最大文件描述符的值 + 1
/*
* 函数名称:flot_to_HEX(float data)
* 函数功能: float 转 16 进制
* 参 数:data 待转换的数据
* 返 回 值: QString 类型
*/
QString MainWindow::flot_to_HEX(float data)
{
uint hex_uint = *(uint *)&data;
// 调整字节顺序
QByteArray byteArray(reinterpret_cast<const char*>(&hex_uint), sizeof(hex_uint));
std::reverse(byteArray.begin(), byteArray.end());
hex_uint = *reinterpret_cast<const uint*>(byteArray.data());
// 将浮点数 f_uint 转换为 8 位的大写 16 进制字符串
QString hexString = QString("%1").arg(hex_uint, 8, 16).toUpper();
// 用正则表达式, 每两个字符之间插入一个空格
hexString.replace(QRegularExpression("(..)"), "\\1 ");
return hexString;
}
QString MainWindow::floatToHex(float data)
{
QByteArray byteArray(reinterpret_cast<const char*>(&data), sizeof(data));
byteArray = byteArray.toHex().toUpper();
// 在每个字节之间添加空格
QString hexString;
for (int i = 0; i < byteArray.size(); ++i)
{
hexString += byteArray.mid(i, 2) + " ";
i += 1;
}
// return hexString.trimmed();
return hexString;
}
十. 项目
1. Json库
GitHub 主页:https://github.com/SunzeY/Shell-in-linux
2. WebServer
GitHub 主页:https://github.com/gaojingcome/WebServer
3. 网盘
GitHub 主页:https://github.com/dongyusheng/cloud-disk
4. 其它项目
https://ac.nowcoder.com/discuss/578948?type=0&order=0&pos=23&page=1
跨平台文件、目录操作
https://hkrb7870j3.feishu.cn/docx/Fvn4d2j6hooOYVxy2k3cZ8qnnlf
- 统计项目文件数量、统计项目代码行数
- 创建目录、创建多级目录,删除目录、复制目录、移动目录等
- 读取文件、复制文件、移动文件、删除文件、获取文件所在目录等
常用功能封装
- 基于 C++11 的技术
- 常用文件操作
- 常用目录操作
- 常用文件流读写操作
- 跨平台
为什么要自己封装呢?
- 标准库 fstream 功能强大,但是使用方面不是很方便
- 目录的操作需要 C++17 的编译器支持,但很多时候生产环境的编译器版本没有那么高
类:File
| 成员函数 | 描述 |
|---|---|
| name | 获取文件名 |
| dir | 获取文件所在目录 |
| create | 创建文件 |
| remove | 删除文件 |
| copy | 复制文件 |
| rename | 文件重命名(移动文件) |
| exists | 判断文件是否存在 |
| clear | 清空文件内容 |
| line | 获取文件行数 |
| size | 获取文件大小 |
| read | 一次性读取文件全部内容 |
| write | 一次性写入文件 |
file_write_stream.h
namespace fs {
class FileWriteStream {
public:
FileWriteStream() = delete;
FileWriteStream(const std::string &name);
FileWriteStream(const FileWriteStream &) = delete;
~FileWriteStream();
bool open();
void close();
bool write_char(const char &data);
bool write_line(const std::string &data);
FileWriteStream &operator = (const FileWriteStream &) = delete;
}
}
file_read_stream.h
namespace fs {
class FileReadStream {
public:
FileReadStream() = delete;
FileReadStream(const std::string &name);
FileReadStream(const FileReadStream &) = delete;
~FileReadStream();
bool open();
void close();
bool read_char(const char &data);
bool read_line(const std::string &data);
FileReadStream &operator = (const FileReadStream &) = delete;
private:
std::string m_name;
}
}
文件流写入操作
类:FileWriteStream
| 成员函数 | 描述 |
|---|---|
| open | 打开文件流 |
| close | 关闭文件流 |
| write_char | 逐个字符写入文件 |
| write_line | 逐行写入文件 |
获取文件名
函数:name
#include <iostream>
#include <fs/file.h>
using namespace yazi::fs;
int main()
{
File file("./../test/a/b/c/1.txt");
std::cout << file.name() << std::endl;
return 0;
}